Intro do Data Science with Python
The Data Processing Pipeline
- Acquisition
- Cleansing
- Transformation
- Analysis
- Storage
Acquisition
The process of loading needed data into the first stage of the pipeline to be used later down the line.
Cleansing
Process of detecting and crrecting corrupt or inaccurate data, or removing uncesessary data.
Transformation
The process of changing the format or structure of the data for analysis. Example: NLP (natural language processing) tools can handle taking a phrase or large text and shredding it into individual words. Other types of transformations like sentiment analysis also exist. It is a text processing technique that generates a number that represents the emotions expressed within a text.
Analysis
Raw data is intepreted to draw conclusions.
Storage
Results generated from analysis need to be stored somewhere. This is typically a file or database.
The Pythonic Way of Data Pipelines
"Pythonic" is an programming ideology that surrounds how Python code should be written. I dont care for it, but its worth understanding.
What makes code pythonic?
- Concise
- Efficent (that's rich)
- Leverages list comprehensions
Example: Multiline Fragment of Text Processing
txt = ''' Eight dollars a week or a million a year - what is
the difference? A mathematician or a wit would give you the
wrong answer. The magi brought valuable gifts, but that was
not among them. - The Gift of the Magi, O'Henry'''
We need to split the text by sentences, creating a list of words for each sentence not including punctuation.
word_lists = [[w.replace(',','') for w in line.split() if w not in ['-']]
for line in txt.replace('?', '.').split('.')]
- The for line in txt loop splits the text into senctences by parsing on the period after replacing any question marks with a period.
- The sentences are then stored in a list.
- Then for w in line loop splits each sentence into individual words and stores them into a larger list.
We should get something like this:
[['Eight', 'dollars', 'a', 'week', 'or', 'a', 'million', 'a',
'year', 'what',
'is', 'the', 'difference'], ['A', 'mathematician', 'or',
'a', 'wit',
'would', 'give', 'you', 'the', 'wrong', 'answer'], ['The',
'magi',
'brought', 'valuable', 'gifts', 'but', 'that', 'was',
'not', 'among',
'them'], ['The', 'Gift', 'of', 'the', 'Magi', "O'Henry"]]
This accomplished data cleaning and transformation. We cleaned the punctuation then normalized the data into a form we wanted (a list of list of words).
Python Data Structures
Lists
Lists are ordered collections of objects (its all objects in Python). Objects are separated by commas and enclosed by brackets. Typically, and Pythonically speaking, lists are inteded to store homogenous data, or data that is related and of the same type. Below we can see lists can hold different objects of different types:
my_list = ['hey', 12, 'how are you', 'c']
They are mutable. So we can add whatever whenever we want to the list.
List Methods
Since lists are are objects in Python, we have some methods to interface with the list.
list.append: Add an object to the end of the listprint(list[i]): Print the data at the i position (not really a method of the list object, but whatever)list.index(object): Get the index of an object in a listlist.insert(i, object): Insert object at i indexlist.count(object): Get the count of object in list
Slice Notation
Lists can be sliced into parts or slices. The slice is a list itself. For example, to print the first three objects in the list using a slice:
print(list[0:3])
This will print the 0th, 1st, and 2nd items in the list. Not the 3rd! The end and end indices in a slice are optional.
print(list[:3]): Same as before and will print the first 3 objects.print(list[3:]): Print the 3rd item and every item following in the listlist[len(list):] = [Object1, Object2]: Add two more objects to the end of the listdel list[5:]: Removes everything with indices 5 and above
List as a Queue
A queue is a data structure that follows first in first out. One end of the queue adds data (enqueue) and the other end removes data (dequeue).
from collections import deque
queue = deque(my_list)
queue.append(1)
print(queue.popleft(), ' - Done!')
list_upd = list(queue)
When calling the construtor of the queue object on a list, the list is has methods specific to the queue class added to the list object. We then add 1 with the append() method, then we remove by calling the popleft() method. It removed the left most item (or the smallest index) and returns it so we can print it with the appended done.
List as a Stack
A stack is similar to a list but data is added and removed in a first in last out approach or last in first out.
my_list = ['Pay bills', 'Tidy up', 'Walk the dog', 'Go to the pharmacy', 'Cook dinner']
stack = []
for task in my_list:
stack.append(task)
while stack:
print(stack.pop(), ' - Done!'))
print('\nThe stack is empty')
There is not stack data structure in this example, but we can get the same utility as a stack from a list using methods like append and pop. A new list is allocated called stack and then for each item in my_list, we append to the stack. Data is then popped off the stack until it is empty and the chores are done.
Lists in NLP
A list and stack can be used to extract all the noun chunks from a text. Words to the left of the noun are dependent on the noun like adj or determiners.
Tuples
Like a list, tuples is a collection of ordered objects. They are immutable. They are typically used to store heterogenous data or data of different types. It is very common to nest tuples in lists.
task_list = ['Pay bills', 'Tidy up', 'Walk the dog', 'Go to the pharmacy', 'Cook dinner']
tm_list = ['8:00', '8:30', '9:30', '10:00', '10:30']
# We can iterate and build the tuple for each item in the task_list
time_task_list = []
for i in range(len(tasks_list)):
tuple = (tm_list[i], tasks_list[i])
time_task_list.append(tuple)
# Or we can use zip
schedule_list = [(tm, task) for tm, task in zip(tm_list, task_list)]
print(schedule_list[1][0])
Using the zip function is more "Pythonic", but it feels like I should iterate to have explicit control, but what do I know? We can also print the second tuple in the list and the first object in the tuple using print(schedule_list[1][0]).
Dictionaries
Dictionaries store key-value pairs, are mutable, and each key is unique.
For example, {'Make': 'Ford', 'Model': 'Mustang', 'Year': 1964}. We can also leveage the list class by appending dictionaries into a list:
dict_list = [
{'time': '8:00', 'name': 'Pay bills'},
{'time': '8:30', 'name': 'Tidy up'},
{'time': '9:30', 'name': 'Walk the dog'},
{'time': '10:00', 'name': 'Go to the pharmacy'},
]
# We can change data inside the dictionaries
dict_list[1]['time'] = '9:00'
setdefault() with Dictionaries
This method provides an easy way to add new data to a dictionary. It takes a key-value pair as the parameter. If the pair already exists, the method returns the value of that key. If the key does not exists, the pair is inserted.
Example: Counting Word Occurrences in NLP
txt = ''' Go is a better language than Python. There is not a thing you can say to
convince me otherwise. You YOU YOU YoU 1 2 3 1 2 3 4 21 11 11 1 1 1 1'''
# Separate all words with a space
txt = txt.replace('.',' ').lower()
# Store in list
word_list = txt.split()
# Distinct count of words
word_counts = {}
# Iterate over the list and look at each word
for word in word_list:
# For each word, setdefault to 0 if not already in the dict
word_counts.setdefault(word, 0)
# Add one to the value mapped to the key (word)
word_counts[word] += 1
print(word_counts)
sorted_word_counts = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
print(sorted_word_counts)
Sets
A set is an unordered collection of unique items. No duplicates. It is defined with curly braces.
random_set = {'America', 'Russia', 'Guam'}
A good use case for sets is casting a list to a set and back to a list to remove duplicates.
lst = [1,2,3,1,1,1,2,3]
lst = list(set(lst))
print(lst) # 1 2 3
The order is not preserved. The list can be sorted.
lst = list(sorted(set(lst), key=lst.index))
Data Science Libraries
Why write all of the code when someone else has done it all already?
Numpy
The Numeric Python Library is nice when working with arrays. A majority of other data science libraries rely on Numpy.
The array is a grid of element of the same type. They are indexed by a tuple of nonnegative integers. They allows for element-wise operations. An element-wise operation is operating on two arrays of the same dimmensions that produce another array of the same dimmensions.
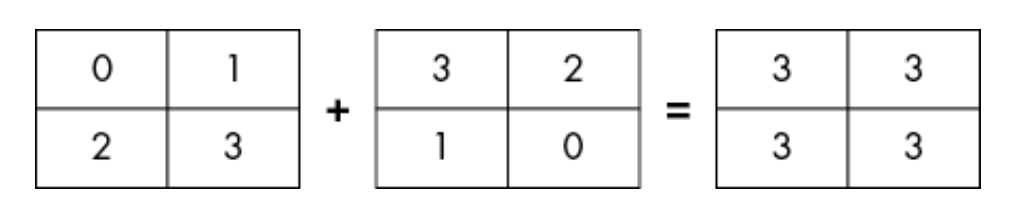
The result array has the same dimmension. The operations are precompiled C code which allows faster execution.
Creating a NumPy Array
import numpy as np
data_1 = [1, 1, 1]
data_2 = [2, 1, 0]
data_3 = [100, 1, 1]
combined_data = np.array([data_1, data_2, data_3])
print(combined_data)
""" Output
[[ 1 1 1]
[ 2 1 0]
[100 1 1]]
"""
A set of lists are passed to the array constructor that are then used to build a 2D numpy array. What happens when the lists are not balanced? Let say we cut the last 1 out of the last list.
ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (3,) + inhomogeneous part.
We can see the interpreter raises a value error. The detected shape should of had 3 elements. What about if we pass a list of strings instead of a list of ints?
data_1 = [1, 1, 1]
data_2 = [2, 1, 0]
data_3 = ['1', '1', '2']
""" Output
[['1' '1' '1']
['2' '1' '0']
['1' '1' '2']]
Kinda weird. We can tell numpy how to handle the conversion.
"""
combined_data = np.array([data_1, data_2, data_3], dtype=int)
# When we specify the type as an int, np will convert all elements to an int.
# NOTE: Converting a string like "sample" can not be handled by numpy and will result
# in a value error.
Pandas
Dataframes are similar to 2D vectors. They can be used to store data similar to a table.
Combining Dataframes
Pandas allows us to merge or join data frame. The syntax is very similar to SQL. If we have a one to one merge, we can rely on the shared indexes between two tables:
emps_salary = emps.join(salary)
print(emps_salary)
Different Types of Joins
Joining index to index is the default behavior. We can get different types of joins passing a how parameter into the join function.
# Inner
emps_salary = emps.join(salary, how='inner')
# Orders
data = [[2608, 9001,35], [2617, 9001,35], [2620, 9001,139],
[2621, 9002,95], [2626, 9002,218]]
orders = pd.DataFrame(data, columns = ['Pono', 'Empno',
'Total'])
emp_orders = emps.merge(orders, how='inner', left_on='Empno', right_on='Empno').set_index('Pono')
Aggregating with groupby()
In pandas, we can groupby similar to SQL.
We can apply a aggregate function like mean() to a column Total and groupby Empno
print(orders.groupby(['Empno'])['Total'].mean())
Scikit-learn
Scikit-learn can be used to take a deep dive into exploratory and predictice analysis with machine learning.
Predictive Analysis
This type of analysis relies on classification and regression. Both of those types of algos need pass data to make predictions about new data.
- Classification: Sorts data into discrete categories
- Regression: Ouputs a contunous range of numerical values
Using Scikit-learn
# 1. Reading in a sample data set as a DataFrame:
import pandas as pd
df = pd.read_csv('/usr/Downloads/sentiment labelled sentences/amazon_cells_labelled.txt', names=['review', 'sentiment'], sep='\t')
# Two columns are specified: one to hold reviews, and one to hold the corresponding sentiment scores
# 2. Splitting the data into two sets: training and test (with a \tab separation)
# Training: Data set to train the model
# Test: Data to test the model
from sklearn.model_selection import train_test_split
reviews = df['reviews'].values
sentiments = df['sentiment'].values
reviews_train, reviews_test, sentiment_train, sentiment_test = train_test_split(sentiments, test_size=0.2, random_state = 500)
- The train_test_split() function splits the data from the CSV. The reviews and each of the sentiment scores is passed into the function and NumPy arrays obtianed from the values property from the Series object from the Dataframe.
- The test_size parameter controls how the CSV will be split into two sets. The 0.2 means 20% of the reviews will be randomly assigned to teh test set (20% to test set 80% to training).
- This parameter is used to control the shuffling applied to the data before splitting. Setting a specific value (like 500) ensures that the split is reproducible; that is, every time you run the code with the same random state, you will get the same split.
Encoding text into Numerical Feature Vectors
In order to train and test models, text data needs a numerical representation. Scikit-learn has a CountVectorizer() function to create a BoW matrix. It converts text data into numerical feature vectors and perform tokenization (separating a text into individual words and punctuation symbols.)
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
vectorizer.fit(reviews)
X_train = vectorizer.transform(reviews_train)
Y_train = vectorizer.transform(reviews_test)
- A vectorizer object is initialized
- The fit method on the vectorizer builds the vocabulary of tokens in the reviews set.
- The transform method transforms the text data in both sets into numerical feature generators
Training and Evaluating the Model
First, the LogisticRegression() classifier can be used to predict sentiment of a review. Logistic regression is a basic and popular algorithm for classification. We can create the classifier object then use the fit() method to train the model given the training data.
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, sentiment_train)
Not that the data is fitted, the model can be evaluated. Labeled data is best for this since the sentiment is known.
accuracy = classifier.score(X_test, sentiment_test)
print(f"Accuracy: {accuracy}")
This score will be a percentage. If the accuracy = 83%, the model is right 83% of the time or 83% accurate.
Making Predictions
new_review = ['I really really hate python now', 'Very good effort, but not a 5 start performace', 'I LOVE IT']
X_new = vectorizer.transform(new_reviews)
print(classifier.predict(X_new))